One unified API for resilient AI delivery
Keep your SDK—change the base URL and key to reach major models with eligible provider fallback.
Switch without rewriting
Keep your tools. Change the endpoint.
Chat Completions
/v1/chat/completions
OpenAI SDK
Responses API
/v1/responses
Codex CLI
Messages API
/v1/messages
Claude Code
Change two settings. Keep shipping.
Point your application, Claude Code, or Codex to Router One without replacing the clients your team already knows.
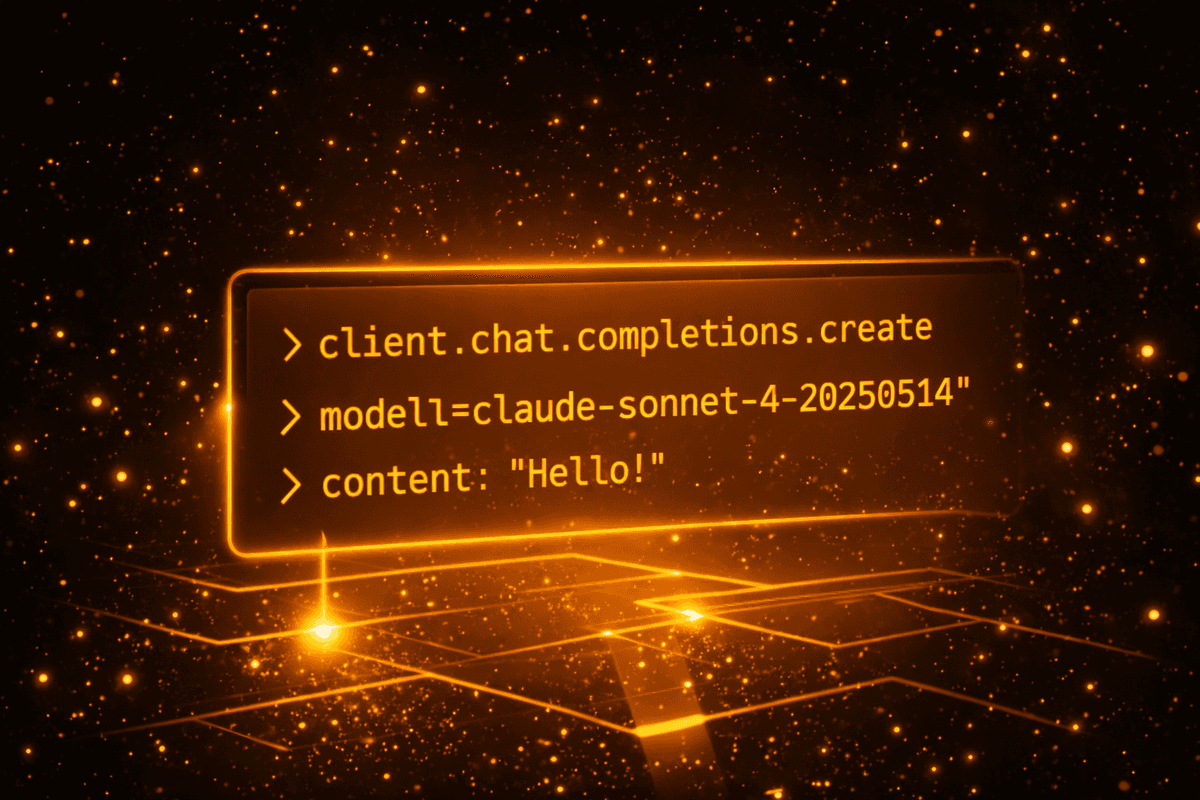
from openai import OpenAI
client = OpenAI(
base_url="https://api.router.one/v1",
api_key="sk-xxx"
)
response = client.chat.completions.create(
model="claude-sonnet-4-20250514",
messages=[{"role": "user", "content": "Hello!"}]
)
# Works with any OpenAI-compatible SDKBuilt for continuity
A failed route does not have to end the request
For retryable provider errors, Router One can try another eligible route serving the same requested model—and record the final result.
Request: demo_req_7f3a
Request
POST /v1/responses · model: example-chat-model
Illustrative internal route sequence
Request accepted
The application asks for one exact example model.
Route A selected
Gateway policy selects an eligible provider route for that model.
Eligible fallback route succeeds
After a retryable Route A error, Route B serves the same requested model; no cross-model substitution is implied.
Final trace recorded
The customer log records the final route and request metrics.
Customer-visible final trace
- Final model
- example-chat-model
- Provider
- Example Route B
- Input tokens
- 512
- Output tokens
- 200
- Latency
- 1,180 ms
- Status
- 200
Illustrative cost ledger
- Input512 tokens · $2.00 / 1M
- $0.0010
- Output200 tokens · $16.00 / 1M
- $0.0032
Customer traces expose the final model, provider, tokens, cost, latency, and status. Intermediate failed attempts remain operations-only and are correlated by request ID.
- Source
- Router One public routing and observability contracts
- Contract reviewed
- Window
- One synthetic request
- Limits
- Synthetic values only—not production traffic, a benchmark, an SLA, or a price quote.
AI billing on your terms
Choose pay-as-you-go flexibility or a predictable subscription, then fund it by card, local payment, or stablecoin.
See how charges are calculatedPay only for what you use
Top up first, then pay the posted rate for actual token usage. Unspent wallet balance does not expire.
Make monthly access predictable
Eligible models in a tier share monthly request quotas; wallet balance covers calls outside plan coverage.
Card, WeChat Pay, or Alipay
Use a card through Stripe, or top up in RMB with the local payment rails your team already uses.
Fund with USDT / USDC
Stablecoin top-ups support cross-border teams, Web3 products, and card-limited workflows on published networks.
Trace every model-call cost to a request and key
Trace failures to one request, attribute spend to the right key, and contain runaway usage before it spreads.
- Debug from the request IDInspect status, model, provider, tokens, cost, and latency before deciding what failed.See a request trace
- Give every workload its own cost trailCreate separate keys for apps, agents, or environments so usage and spend stay attributable to the right workload.See per-key cost tracking
- Limit one key without stopping the restSpend caps, rate limits, and per-minute token ceilings contain one key without stopping unrelated applications.Review key guardrails
Start with the use case you need
Explore routing, cost control, coding-tool access, billing, and migration guides for your next integration.
The three questions teams ask before switching
Confirm network access, data handling, and product boundaries before you send production traffic.
Can my mainland China team call Router One directly?
Yes, without a VPN or proxy. See the published China latency benchmark for its measurement window, methodology, and limitations; actual performance varies by region and network.
Do prompts or model responses land in Router One storage?
No. Router One forwards request content in real time and does not persist it; the data-retention page lists which metadata is retained and for how long.
What stays in my application?
Agent workflows, state, and tool execution stay in your application or orchestration framework. Router One handles each model call.
Need another answer? Read all FAQs
Your next model call can run through Router One
Keep your SDK, start with one API key, and expand model coverage when your product needs it.
